
비전 언어 모델 쉽게 이해하기
이 글은 Hugging Face 블로그의 Vision Language Models Explained를 한국어로 번역한 글입니다.
비전 언어 모델 쉽게 이해하기
[!TIP] 이 블로그 포스트는 2024년 4월에 작성되었으며, 비전 언어 모델의 내부 구조에 대한 훌륭한 소개, 기존 비전 언어 모델들의 개요, 그리고 이를 파인튜닝하는 방법을 제공합니다. 더 많은 기능과 모델을 다루는 2025년 4월 업데이트를 작성했으니, 이 글도 꼭 확인해보세요!
비전 언어 모델은 이미지와 텍스트로부터 동시에 학습하여 시각적 질의응답(VQA)부터 이미지 캡셔닝까지 다양한 작업을 수행할 수 있는 모델입니다. 이 포스트에서는 비전 언어 모델의 주요 구성 요소들을 살펴보고, 전체적인 개요를 파악하며, 작동 원리를 이해하고, 적합한 모델을 찾는 방법, 추론에 사용하는 방법, 그리고 trl의 새 버전을 사용해 쉽게 파인튜닝하는 방법을 다룹니다!
비전 언어 모델(Vision Language Model)이란?
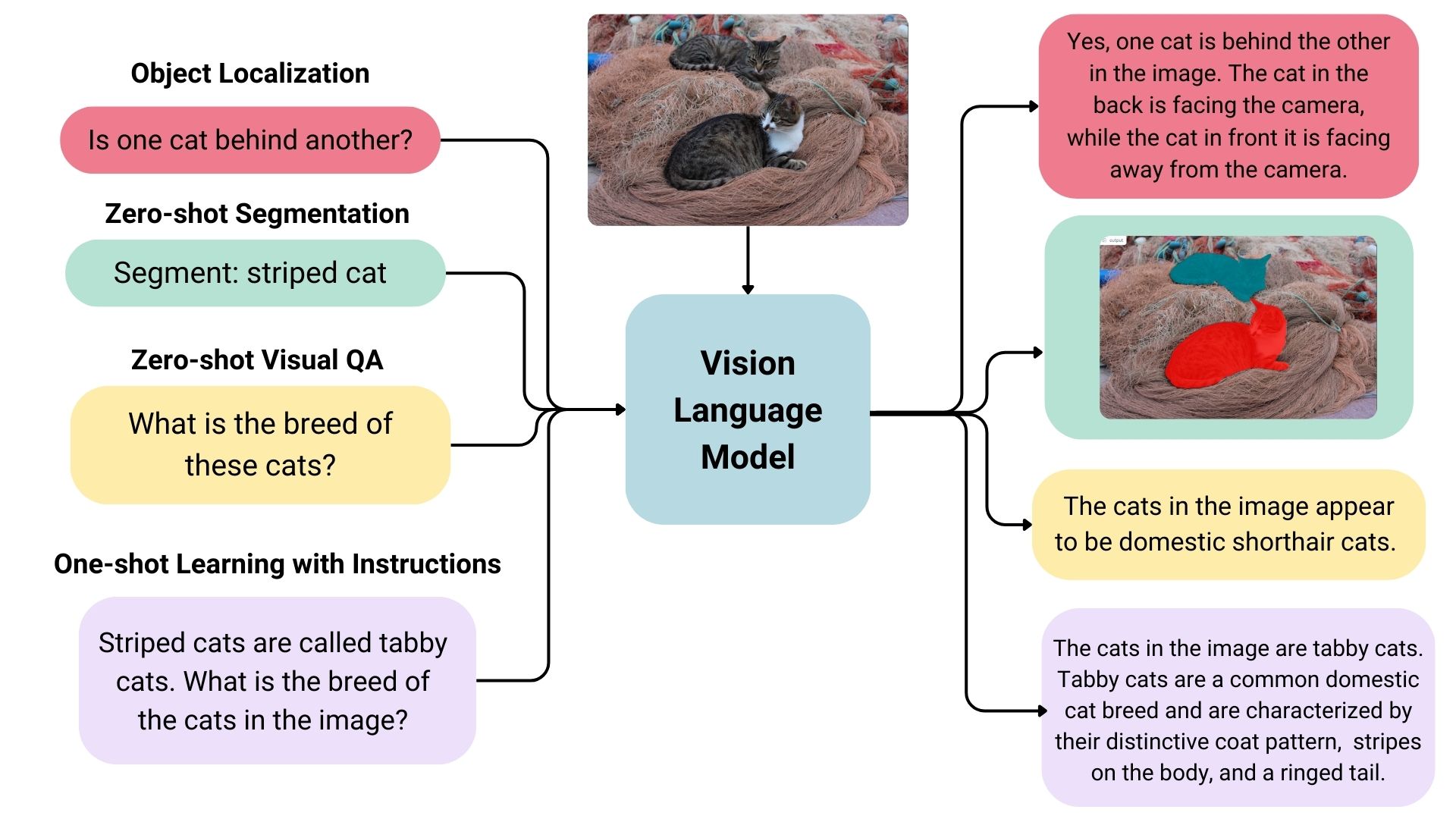
비전 언어 모델은 이미지와 텍스트로부터 학습할 수 있는 멀티모달(Multimodal) 모델로 폭넓게 정의됩니다. 이들은 이미지와 텍스트를 입력으로 받아 텍스트를 생성하는 생성형(generative) 모델의 일종입니다. 거대 비전 언어 모델은 우수한 제로샷(zero-shot) 능력을 가지고 있으며, 일반화 성능이 뛰어나고, 문서나 웹 페이지 등 다양한 유형의 이미지에 대해서도 사용할 수 있습니다. 활용 사례로는 이미지에 대해 대화하기, 명령 기반 이미지 인식, 시각적 질의응답(VQA), 문서 이해, 이미지 캡셔닝 등이 있습니다. 일부 비전 언어 모델은 이미지의 공간적 특성 또한 포착할 수 있습니다. 이러한 모델들은 특정 대상을 탐지하거나 분할하라는 프롬프트에 따라 바운딩 박스(bounding box) 또는 세그멘테이션 마스크(segmentation mask)를 출력할 수 있으며, 서로 다른 객체의 상대적 또는 절대적 위치를 파악하거나 그에 대한 질문에 답변할 수도 있습니다. 현재 존재하는 거대 비전 언어 모델들은 학습에 사용된 데이터, 이미지 인코딩 방식, 그리고 그로 인한 모델의 능력 측면에서 매우 다양합니다.
오픈소스 비전 언어 모델 살펴보기
Hugging Face Hub에는 많은 오픈소스 비전 언어 모델이 있습니다. 몇몇 주요한 모델들은 아래 표에 나와 있습니다.
- Base 모델과 대화 모드에서 사용할 수 있도록 채팅용으로 파인튜닝된 모델이 있습니다.
- 이러한 모델들 중 일부는 모델 환각(hallucination)을 줄이는 “그라운딩(grounding)” 기능을 가지고 있습니다.
- 별도로 명시되지 않는 한, 모든 모델은 영어로 학습되었습니다.
| 모델 | 허용 라이선스 | 모델 크기 | 이미지 해상도 | 추가적인 기능 |
|---|---|---|---|---|
| LLaVA 1.6 (Hermes 34B) | ✅ | 34B | 672x672 | |
| deepseek-vl-7b-base | ✅ | 7B | 384x384 | |
| DeepSeek-VL-Chat | ✅ | 7B | 384x384 | 대화 |
| moondream2 | ✅ | ~2B | 378x378 | |
| CogVLM-base | ✅ | 17B | 490x490 | |
| CogVLM-Chat | ✅ | 17B | 490x490 | 그라운딩, 대화 |
| Fuyu-8B | ❌ | 8B | 300x300 | 이미지 내 텍스트 탐지 |
| KOSMOS-2 | ✅ | ~2B | 224x224 | 그라운딩, 제로샷 객체 탐지 |
| Qwen-VL | ✅ | 4B | 448x448 | 제로샷 객체 탐지 |
| Qwen-VL-Chat | ✅ | 4B | 448x448 | 대화 |
| Yi-VL-34B | ✅ | 34B | 448x448 | 2개 국어 (영어, 중국어) |
적합한 비전 언어 모델 찾기
자신의 사용 사례에 가장 적합한 모델을 선택하는 방법은 여러 가지가 있습니다.
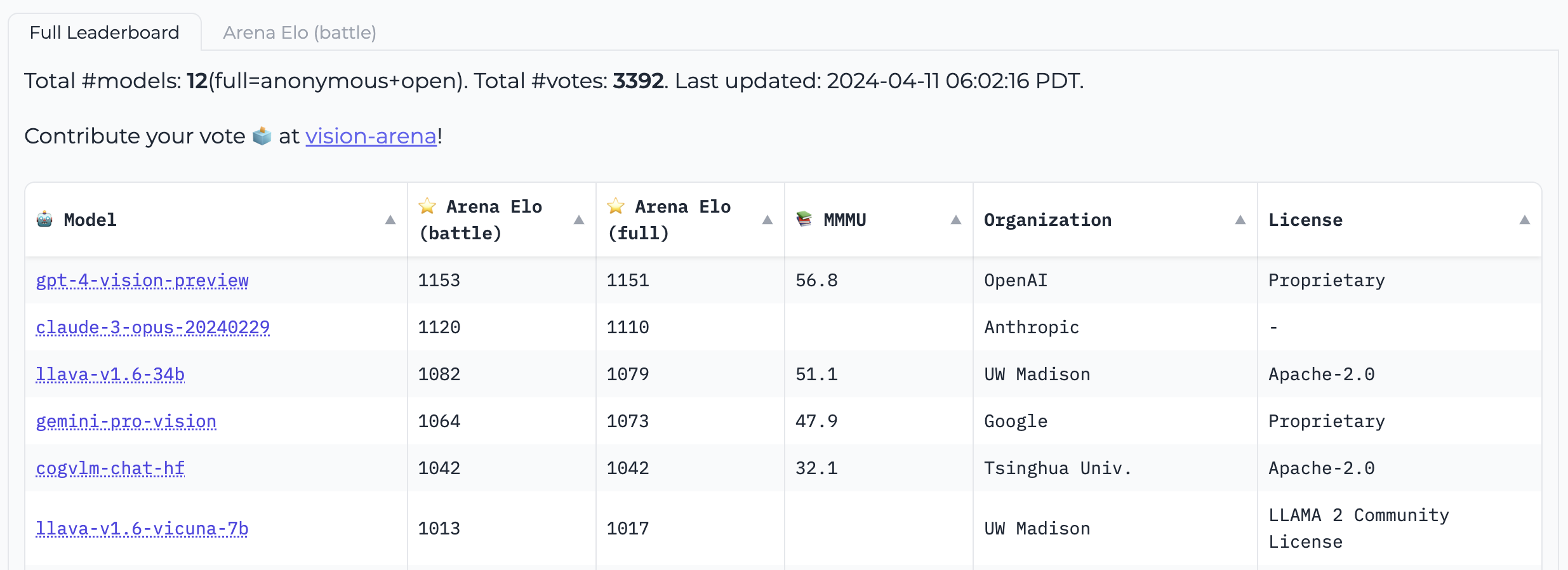
Vision Arena는 모델 출력에 대한 익명 투표만을 기반으로 하는 리더보드로, 지속적으로 업데이트됩니다. 이 아레나에서 사용자는 이미지와 프롬프트를 입력하면, 두 개의 서로 다른 모델의 출력이 무작위로 익명 제공되며, 사용자는 선호하는 출력을 선택할 수 있습니다. 이러한 과정을 통해 리더보드는 전적으로 인간의 선호도에 기반하여 구성됩니다.
Vision Arena
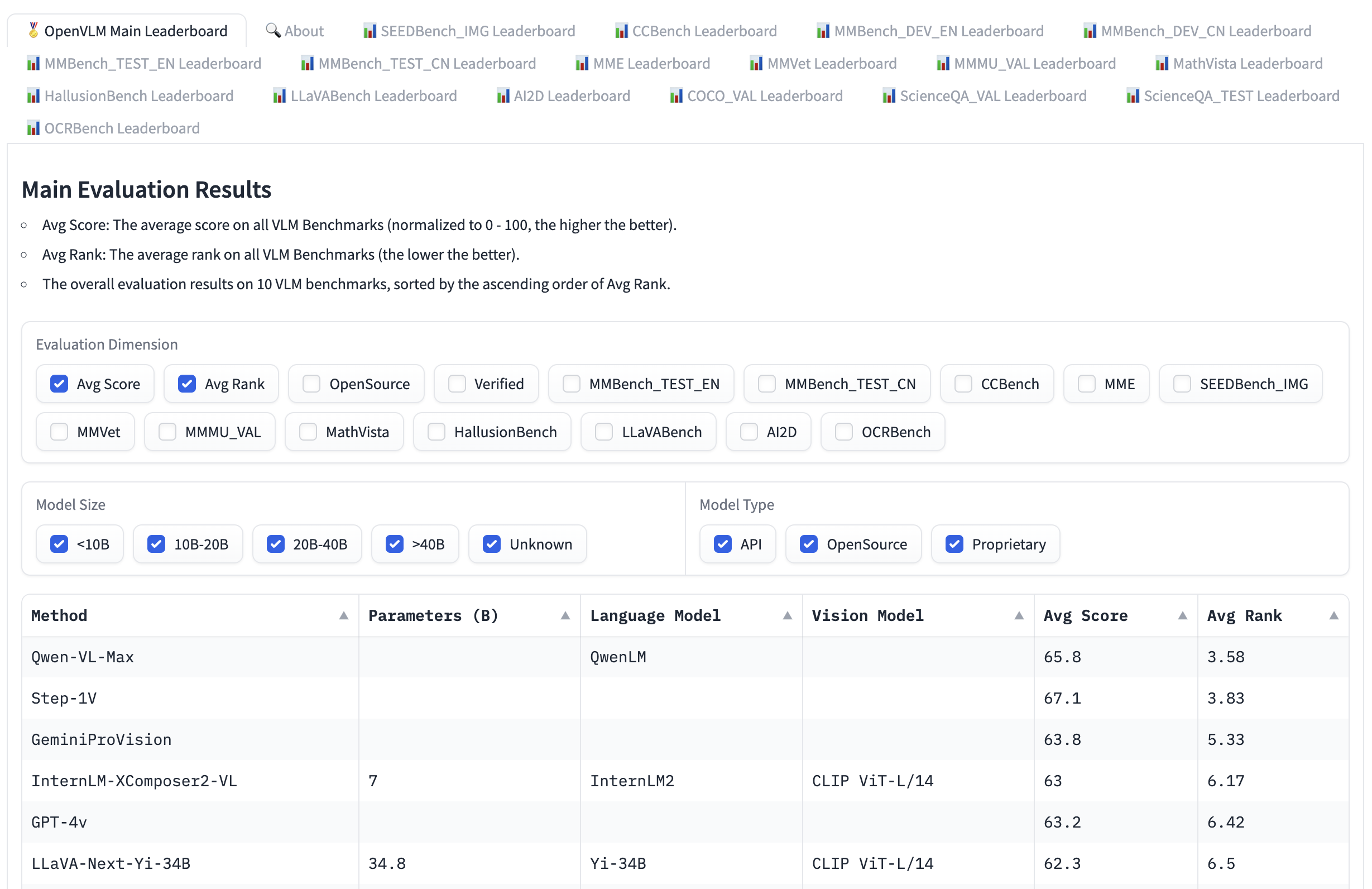
Open VLM 리더보드는 비전 언어 모델들이 다양한 평가 지표와 평균 점수에 따라 순위가 매겨지는 또 다른 리더보드입니다. 모델 크기, 오픈소스 여부에 따라 모델을 필터링하고, 다양한 평가 지표에 대한 순위를 확인할 수도 있습니다.
Open VLM 리더보드
VLMEvalKit은 비전 언어 모델에서 Open VLM 리더보드의 벤치마크를 실행하기 위한 툴킷입니다. 또 다른 평가 도구는 LMMS-Eval로, Hugging Face Hub에 호스팅된 데이터셋을 사용하여 선택한 Hugging Face 모델을 평가할 수 있는 표준 커맨드 라인 인터페이스(CLI)를 제공합니다. 아래와 같이 사용할 수 있습니다.
accelerate launch --num_processes=8 -m lmms_eval --model llava --model_args pretrained="liuhaotian/llava-v1.5-7b" --tasks mme,mmbench_en --batch_size 1 --log_samples --log_samples_suffix llava_v1.5_mme_mmbenchen --output_path ./logs/
Vision Arena와 Open VLM 리더보드는 제출된 모델만 확인할 수 있으며, 새로운 모델을 추가하려면 업데이트가 필요합니다. 추가 모델을 찾고 싶다면, Hub에서 image-text-to-text 태스크로 모델을 탐색할 수 있습니다.
리더보드에는 비전 언어 모델을 평가하기 위한 다양한 벤치마크가 있습니다. 그 중 몇 가지를 살펴보겠습니다.
MMMU
MMMU(A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI)는 비전 언어 모델을 평가하기 위한 가장 종합적인 벤치마크입니다. 예술, 공학 등 다양한 분야에서 대학 수준의 지식과 추론 능력을 요구하는 11,500개의 멀티모달 문제가 포함되어 있습니다.
MMBench
MMBench는 OCR, 객체 위치 추정 등 20가지 다양한 능력을 평가하기 위한 3,000개의 객관식 문제로 구성된 평가 벤치마크입니다. 해당 논문에서는 CircularEval이라는 평가 전략도 함께 제안하는데, 이는 질문의 선택지를 여러 조합으로 섞은 뒤, 모델이 매번 올바른 답을 일관되게 선택할 수 있는지를 평가하는 방식입니다. 이외에도 다양한 도메인별로 특화된 벤치마크들이 존재합니다. 예를 들어, MathVista(시각적 수학 추론), AI2D(도표 이해), ScienceQA(과학 질의 응답), OCRBench(문서 이해) 등이 있습니다.
기술적 세부사항
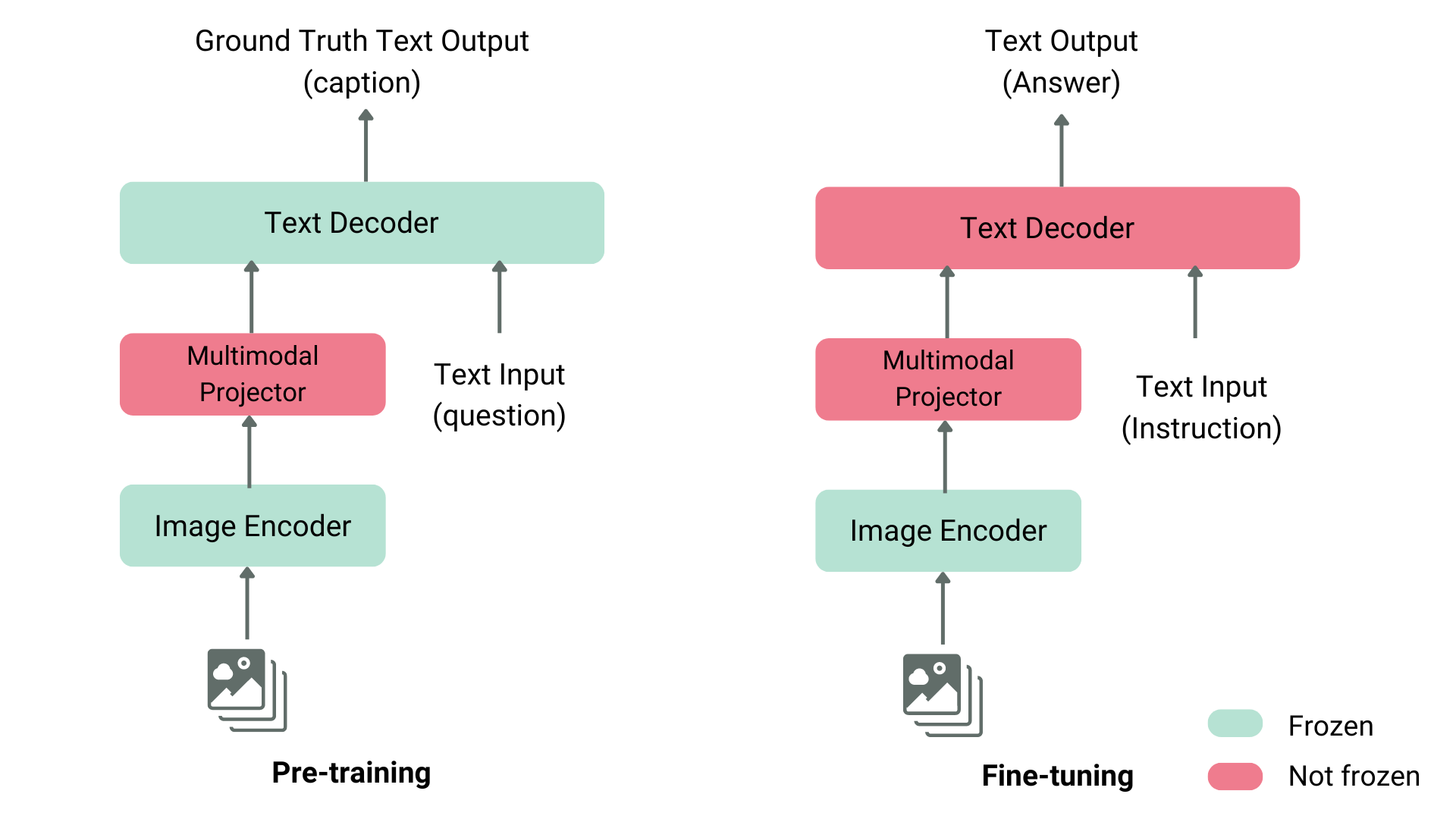
비전 언어 모델을 사전학습하는 방법은 여러 가지가 있습니다. 핵심 아이디어는 이미지와 텍스트 표현을 통합하고, 이를 텍스트 디코더에 입력해 생성 작업을 하도록 하는 것입니다. 가장 일반적이고 대표적인 모델들은 이미지 인코더(image encoder), 이미지와 텍스트 표현을 정렬하기 위한 임베딩 프로젝터(embedding projector, 보통 밀집 신경망), 그리고 텍스트 디코더(text decoder)로 구성되며, 이 순서로 쌓여 있습니다. 학습 방식은 모델마다 조금씩 다르게 설계됩니다.
예를 들어, LLaVA는 CLIP 이미지 인코더, 멀티모달 프로젝터, 그리고 Vicuna 텍스트 디코더로 구성됩니다. LLaVA의 저자들은 이미지와 캡션으로 구성된 데이터셋을 GPT-4에 입력하여, 캡션과 이미지에 관련된 질문을 자동으로 생성했습니다. 그 후, 이미지 인코더와 텍스트 디코더는 고정(freeze)하고, 멀티모달 프로젝터만 학습시켰습니다. 이때 모델에 이미지와 GPT-4가 생성한 질문을 입력하고, 모델의 출력이 정답 캡션과 일치하도록 학습했습니다. 프로젝터의 사전학습이 끝난 뒤에는 이미지 인코더를 계속 고정한 채, 텍스트 디코더와 프로젝터를 함께 학습시켰습니다. 이런 단계적 사전학습과 파인튜닝 방식은 현재 비전 언어 모델을 학습하는 가장 일반적이고 효과적인 접근법으로 사용되고 있습니다.
일반적인 비전 언어 모델의 구조
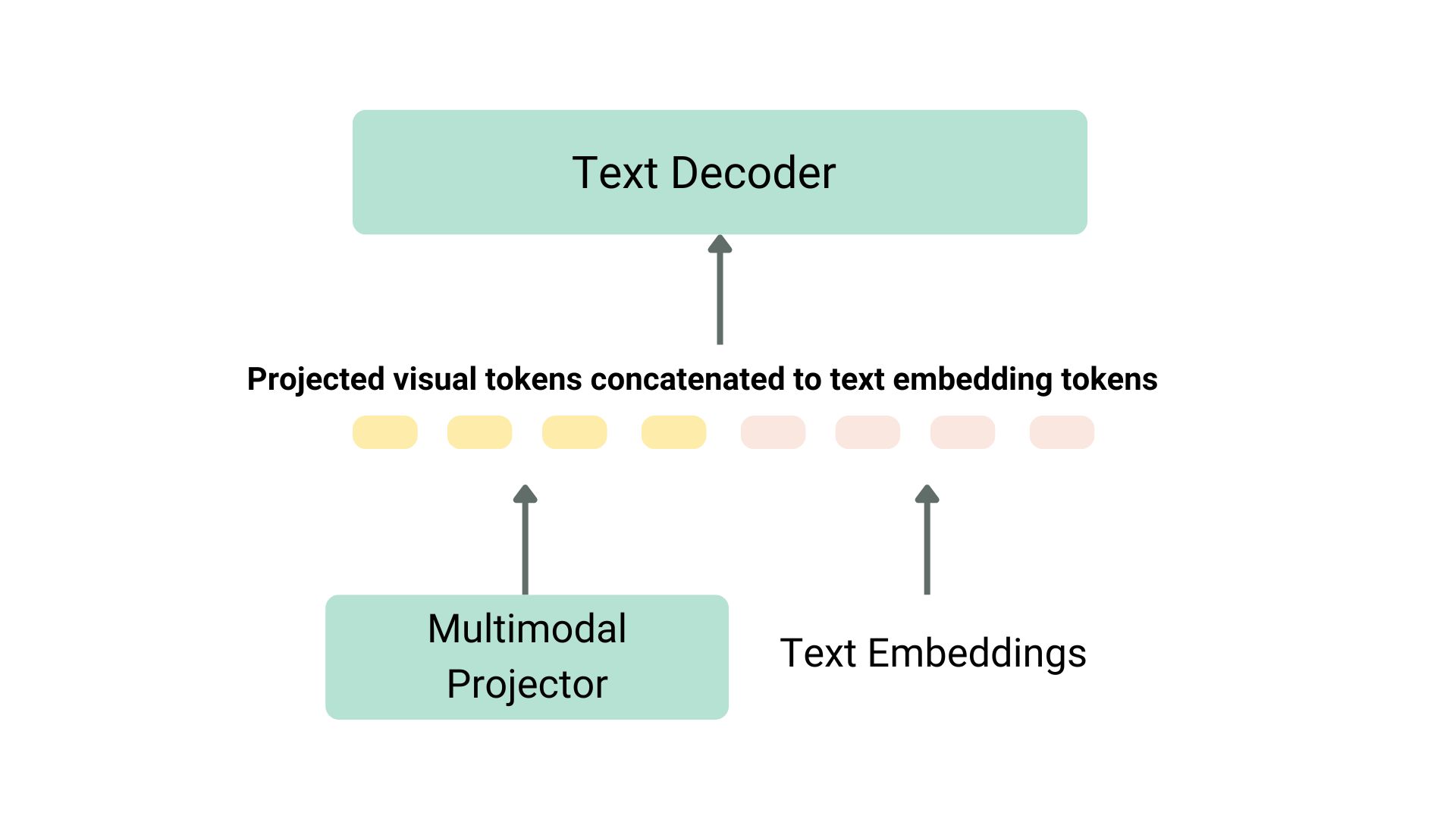
프로젝션과 텍스트 임베딩은 위와 같이 연결됩니다
또 다른 예로 KOSMOS-2가 있습니다. 이 모델의 저자들은 LLaVA와 같은 사전학습 방식과 달리, 모델 전체를 엔드투엔드(end-to-end)로 완전히 학습시키는 방식을 선택했습니다. 이는 계산 비용 측면에서 훨씬 더 비싸고 부담이 큽니다. 이후 저자들은 모델 정렬을 위해 언어로만 인스트럭션 파인튜닝을 수행했습니다. 또 다른 예로 Fuyu-8B는 아예 이미지 인코더를 사용하지 않습니다. 대신, 이미지 패치를 직접 프로젝션 레이어에 입력하고, 그 결과로 나온 시퀀스를 자가회귀(auto-regressive) 디코더를 통해 처리합니다.
대부분의 경우, 비전 언어 모델을 처음부터 사전학습할 필요는 없습니다. 이미 공개된 모델을 활용하거나, 자신의 사용 사례에 맞게 파인튜닝하는 것으로 충분합니다. 이후 섹션에서는 이러한 모델들을 Transformers 라이브러리를 사용해 다루는 방법과, SFTTrainer를 이용해 파인튜닝하는 방법을 살펴보겠습니다.
transformers를 통해 비전 언어 모델 사용하기
아래와 같이 LlavaNext 모델을 사용해 Llava로 추론할 수 있습니다.
먼저, 모델과 프로세서를 초기화해봅시다.
from transformers import LlavaNextProcessor, LlavaNextForConditionalGeneration
import torch
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
processor = LlavaNextProcessor.from_pretrained("llava-hf/llava-v1.6-mistral-7b-hf")
model = LlavaNextForConditionalGeneration.from_pretrained(
"llava-hf/llava-v1.6-mistral-7b-hf",
torch_dtype=torch.float16,
low_cpu_mem_usage=True
)
model.to(device)
이제 이미지와 텍스트 프롬프트를 프로세서에 전달한 뒤, 처리된 입력값을 generate에 전달합니다. 각 모델은 고유한 프롬프트 템플릿을 사용하므로, 성능 저하를 피하기 위해 반드시 올바른 템플릿을 사용해야 합니다.
from PIL import Image
import requests
url = "https://github.com/haotian-liu/LLaVA/blob/1a91fc274d7c35a9b50b3cb29c4247ae5837ce39/images/llava_v1_5_radar.jpg?raw=true"
image = Image.open(requests.get(url, stream=True).raw)
prompt = "[INST] <image>\nWhat is shown in this image? [/INST]"
inputs = processor(prompt, image, return_tensors="pt").to(device)
output = model.generate(**inputs, max_new_tokens=100)
decode를 호출해 출력 토큰을 디코딩합니다.
print(processor.decode(output[0], skip_special_tokens=True))
TRL을 활용해 비전 언어 모델 파인튜닝하기
TRL의 SFTTrainer가 이제 비전 언어 모델을 실험적으로 지원하기 시작했습니다! 여기서는 llava-instruct 데이터셋을 사용해 Llava 1.5 VLM 모델에 대해 SFT를 수행하는 예시를 제공합니다. 이 데이터셋은 26만 개의 이미지-대화 쌍으로 구성되어 있습니다.
데이터셋은 사용자와 어시스턴트 간의 상호작용을 메시지 시퀀스 형태로 구성합니다. 예를 들어, 각 대화는 사용자가 질문하는 이미지와 짝지어져 있습니다.
이 실험적인 지원을 VLM 학습에 적용해보기 위해서는 pip install -U trl로 TRL의 최신 버전을 설치해야 합니다.
전체 예시 스크립트는 여기서 확인할 수 있습니다.
from trl.commands.cli_utils import SftScriptArguments, TrlParser
parser = TrlParser((SftScriptArguments, TrainingArguments))
args, training_args = parser.parse_args_and_config()
인스트럭션 파인튜닝을 위해 대화 템플릿을 초기화합니다.
LLAVA_CHAT_TEMPLATE = """A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. {% for message in messages %}{% if message['role'] == 'user' %}USER: {% else %}ASSISTANT: {% endif %}{% for item in message['content'] %}{% if item['type'] == 'text' %}{{ item['text'] }}{% elif item['type'] == 'image' %}<image>{% endif %}{% endfor %}{% if message['role'] == 'user' %} {% else %}{{eos_token}}{% endif %}{% endfor %}"""
이제 모델과 토크나이저를 초기화합니다.
from transformers import AutoTokenizer, AutoProcessor, TrainingArguments, LlavaForConditionalGeneration
import torch
model_id = "llava-hf/llava-1.5-7b-hf"
tokenizer = AutoTokenizer.from_pretrained(model_id)
tokenizer.chat_template = LLAVA_CHAT_TEMPLATE
processor = AutoProcessor.from_pretrained(model_id)
processor.tokenizer = tokenizer
model = LlavaForConditionalGeneration.from_pretrained(model_id, torch_dtype=torch.float16)
텍스트와 이미지 쌍을 묶어주기 위해 데이터 콜레이터를 생성합니다.
class LLavaDataCollator:
def __init__(self, processor):
self.processor = processor
def __call__(self, examples):
texts = []
images = []
for example in examples:
messages = example["messages"]
text = self.processor.tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=False
)
texts.append(text)
images.append(example["images"][0])
batch = self.processor(texts, images, return_tensors="pt", padding=True)
labels = batch["input_ids"].clone()
if self.processor.tokenizer.pad_token_id is not None:
labels[labels == self.processor.tokenizer.pad_token_id] = -100
batch["labels"] = labels
return batch
data_collator = LLavaDataCollator(processor)
데이터셋을 불러옵니다.
from datasets import load_dataset
raw_datasets = load_dataset("HuggingFaceH4/llava-instruct-mix-vsft")
train_dataset = raw_datasets["train"]
eval_dataset = raw_datasets["test"]
모델, 데이터셋 분할, PEFT 설정, 그리고 데이터 콜레이터를 전달해 SFTTrainer를 초기화한 뒤 train()을 호출합니다. 최종 체크포인트를 Hugging Face Hub에 업로드하려면 push_to_hub()를 호출합니다.
from trl import SFTTrainer
trainer = SFTTrainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
dataset_text_field="text", # 더미 필드 필요
tokenizer=tokenizer,
data_collator=data_collator,
dataset_kwargs={"skip_prepare_dataset": True},
)
trainer.train()
모델을 저장한 뒤 Hugging Face Hub에 업로드합니다.
trainer.save_model(training_args.output_dir)
trainer.push_to_hub()
학습된 모델은 여기에서 확인할 수 있습니다.
감사의 글
이 블로그 게시물에 대한 리뷰와 제안을 해주신 Pedro Cuenca, Lewis Tunstall, Kashif Rasul, 그리고 Omar Sanseviero께 감사드립니다.

열린 프로젝트

