
MCP for Research: AI와 연구 도구 연결하기
이 글은 Hugging Face 블로그의 MCP for Research: How to Connect AI to Research Tools를 한국어로 번역한 글입니다.
MCP for Research: AI와 연구 도구(Research Tools) 연결하기
학술 연구에서는 논문, 코드, 관련 모델과 데이터셋을 찾는 연구 탐색(research discovery)이 빈번하게 일어납니다. 보통 연구자는 arXiv, GitHub, Hugging Face와 같은 여러 플랫폼을 오가며 관련 정보를 직접 찾아 연결해야 합니다.
Model Context Protocol (MCP)은 에이전틱(Agentic) 모델이 외부 도구 및 데이터 소스와 상호작용할 수 있도록 하는 표준 프로토콜입니다. 연구 탐색에서 MCP는 AI가 자연어 요청을 통해 연구 도구를 활용할 수 있게 함으로써, 플랫폼 간 전환과 상호 참조(cross-referencing) 과정을 자동으로 처리할 수 있도록 합니다.
연구 탐색: 세 가지 추상화 계층
소프트웨어 개발과 마찬가지로, 연구 탐색 과정도 추상화 계층으로 나누어 볼 수 있습니다.
1. 수동 연구 (Manual Research)
가장 낮은 추상화 계층에서는 연구자가 직접 검색하고, 관련 정보를 수작업으로 상호 참조합니다.
# 일반적인 워크플로우:
1. arXiv에서 논문 찾기
2. GitHub에서 구현 코드 검색
3. Hugging Face에서 모델/데이터셋 확인
4. 저자와 인용 관계 상호 참조
5. 수동으로 결과 정리
이러한 수동적인 접근 방식은 여러 연구 주제를 추적하거나 문헌을 체계적으로 검토할 때 비효율적입니다. 여러 플랫폼에서 검색을 반복하고, 메타데이터를 추출하며 정보를 교차 검증하는 과정은 스크립트를 통한 자동화를 필요로 하게 됩니다.
2. 스크립트 도구 (Scripted Tools)
Python 스크립트를 활용하면 웹 요청 처리, 응답 파싱, 결과 정리를 통해 연구 탐색 과정을 자동화할 수 있습니다.
# research_tracker.py
def gather_research_info(paper_url):
paper_data = scrape_arxiv(paper_url)
github_repos = search_github(paper_data['title'])
hf_models = search_huggingface(paper_data['authors'])
return consolidate_results(paper_data, github_repos, hf_models)
# 조사하려는 논문마다 실행
results = gather_research_info("https://arxiv.org/abs/2103.00020")
research tracker는 이러한 스크립트를 기반으로 한 체계적인 연구 탐색 자동화의 예시를 보여줍니다.
스크립트는 수동 연구보다 빠르지만, API 변경, 요청 제한(rate limits) 또는 파싱 오류로 인해 데이터를 자동으로 수집하지 못하는 경우가 많습니다. 인간의 감독이 없으면 관련 결과를 놓치거나 불완전한 정보를 반환할 수 있습니다.
3. MCP 통합 (MCP Integration)
MCP는 자연어를 통해 AI 시스템이 이러한 Python 도구들에 접근할 수 있도록 합니다.
# 연구 지시문 예시
최근 6개월 내에 발표된 Transformer 아키텍처 관련 논문을 찾아주세요:
- 구현 코드가 공개되어 있어야 함
- 사전 학습(pretrained) 모델이 포함된 논문에 집중
- 가능한 경우 성능 벤치마크 포함
AI는 여러 도구를 조합하고, 누락된 정보를 보완하며, 결과를 분석합니다.
# AI 워크플로우:
# 1. Research Tracker 도구 활용
# 2. 누락된 정보 검색
# 3. 다른 MCP 서버와 상호 참조 수행
# 4. 연구 목표와의 관련성 평가
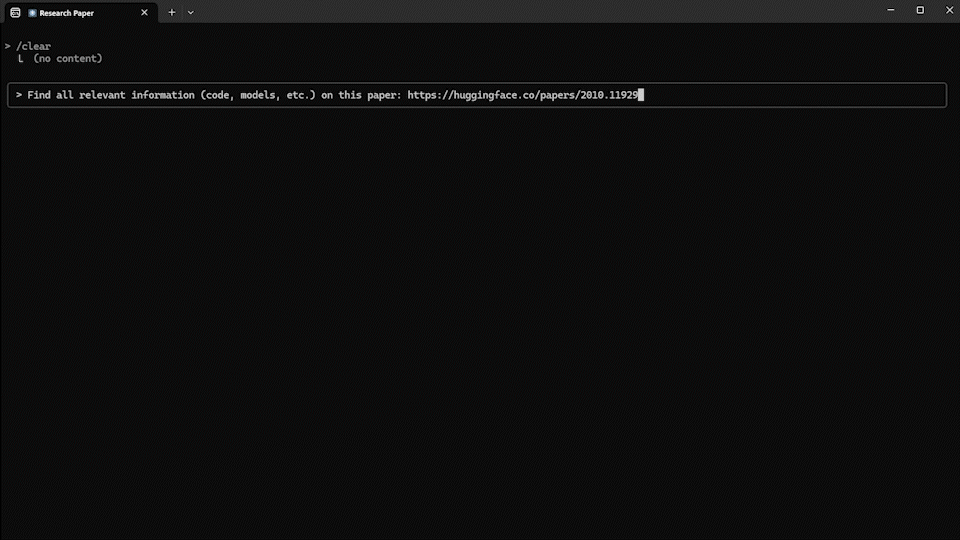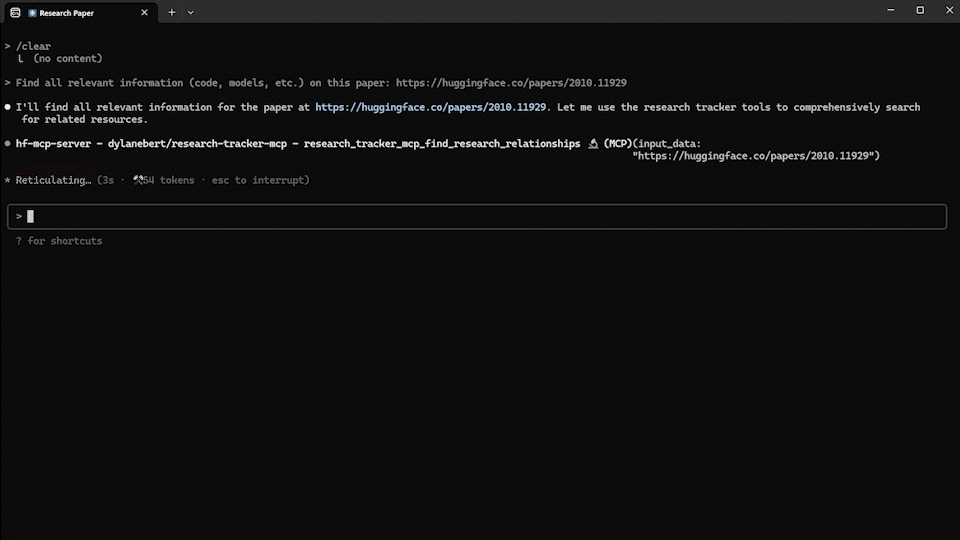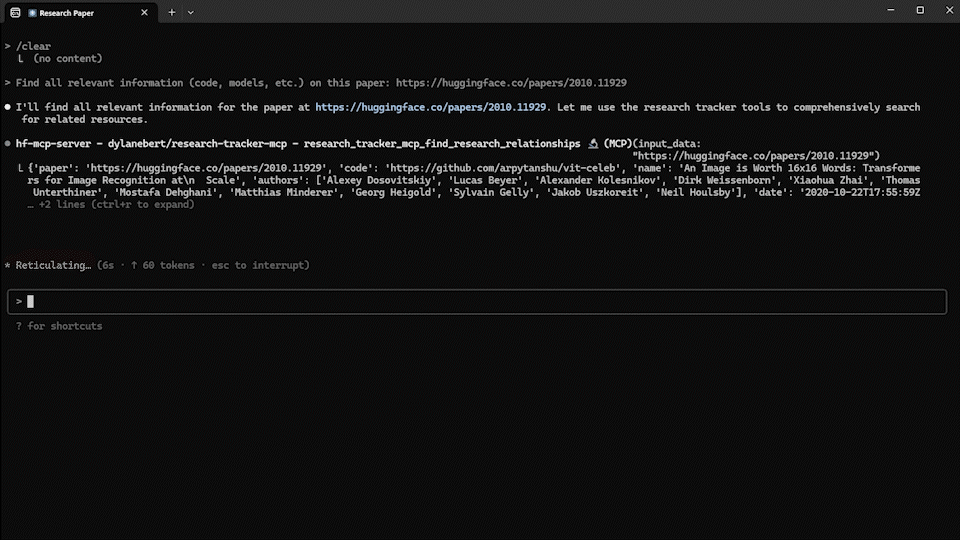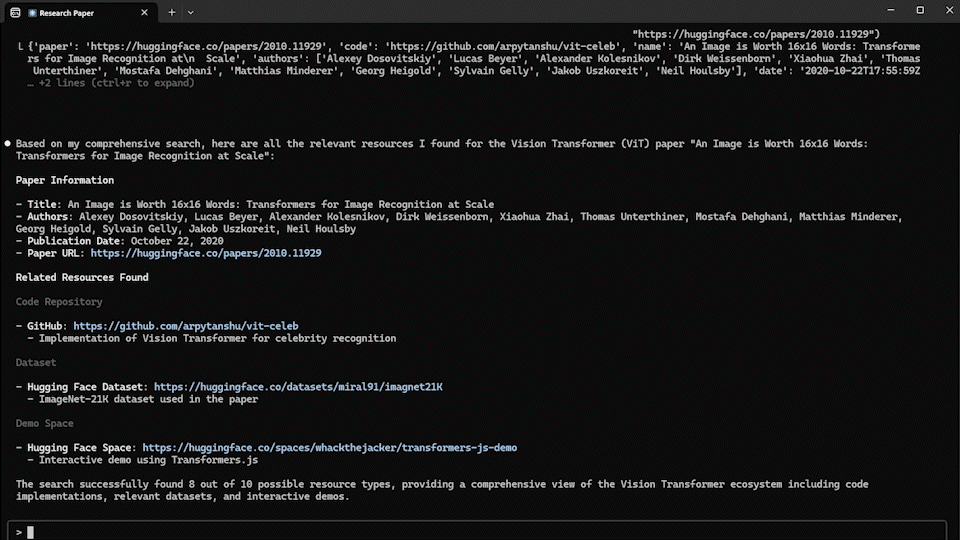
user: "이 논문과 관련된 모든 정보(코드, 모델 등)를 찾아줘: https://huggingface.co/papers/2010.11929"
ai: # 여러 도구를 결합하여 완전한 정보 수집
이는 스크립트 단계보다 한 단계 높은 추상화 수준으로 볼 수 있으며, 이때 “프로그래밍 언어”는 자연어가 됩니다. 이는 Software 3.0 개념과 유사하며, 여기서 자연어로 하는 연구 지시가 실제 소프트웨어 구현 역할을 합니다.
다만, 스크립트와 동일한 한계를 가지고 있습니다.
- 수동 연구보다 빠르지만, 인간의 감독이 없으면 오류가 발생할 수 있음
- 결과의 품질은 구현에 따라 달라짐
- 하위 계층(수동 및 스크립트 방식 모두)을 깊이 이해할수록 더 나은 구현이 가능
설정 및 사용법
빠른 설정
Research Tracker MCP를 추가하는 가장 쉬운 방법은 Hugging Face MCP 설정을 이용하는 것입니다:
- huggingface.co/settings/mcp 접속
- 사용 가능한 도구 목록에서 “research-tracker-mcp” 검색
- 클릭하여 도구에 추가
- 사용하는 클라이언트(Claude Desktop, Cursor, Claude Code, VS Code 등)에 맞는 설치 안내에 따라 진행
이 워크플로우는 Hugging Face MCP 서버를 활용하며, Hugging Face Spaces를 MCP 도구로 사용하는 표준 방식입니다. 설정 페이지는 각 클라이언트에 맞는 구성을 자동으로 생성하여 항상 최신 상태로 제공합니다.
더 알아보기
시작하기:
- Hugging Face MCP 코스 - 기본 개념부터 직접 MCP 도구를 만드는 과정까지 다루는 종합 가이드
- MCP 공식 문서 - 프로토콜 사양 및 아키텍처
직접 만들어보기:
- Gradio MCP 가이드 - Python 함수를 MCP 도구로 변환하기
- Hugging Face MCP 서버 구축 - 실제 프로덕션 구현 사례
커뮤니티:
- Hugging Face Discord - MCP 개발 관련 토론
연구 탐색을 자동화할 준비가 되었나요? Research Tracker MCP를 사용해 보거나, 위의 자료를 참고해 직접 나만의 연구 도구를 만들어보세요.

열린 프로젝트

